

SAM4MLLM:结合多模态大型语言模型和SAM实现高精度引用表达分割 | ECCV'24
发布: 更新时间:2024-11-13 10:17:26
来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: SAM4MLLM: Enhance Multi-Modal Large Language Model for Referring Expression Segmentation

-
论文地址:
https://arxiv.org/abs/2409.10542
-
论文代码:
https://github.com/AI-Application-and-Integration-Lab/SAM4MLLM
创新点
-
提出了一种允许
MLLM
理解像素级细节的方法
SAM4MLLM
,无需改变
MLLM
模型架构、引入新标记或使用额外损失,该方法简单但对引用表达分割(
RES
)非常有效。 -
为了连接
MLLM
和
SAM
,引入了一种新颖的方法,通过主动询问语言系统来获取提示点线索。 -
在各种
RES
基准上进行实验,包括
RES
数据集、
GRES
和
ReasonSeg
,验证了
SAM4MLLM
的有效性,并展示了其在处理复杂像素感知任务中的优良性能。
内容概述
SAM4MLLM
是一种创新的方法,集成
Segment Anything Model
(
SAM
)与多模态大型语言模型(
MLLMs
)以实现像素感知任务。
-
首先,在
MLLM
训练数据集中引入像素级信息,而不改变原有的
MLLM
架构,这使得
MLLM
能够使用与主流
LLM
相同的文本交叉熵损失来理解像素级信息。 -
其次,考虑到输入分辨率限制和模型架构未明确设计用于视觉任务,
MLLM
在像素表达方面可能存在的潜在限制。进一步利用
SAM
增强输出,通过后处理
MLLM
的输出以相对简单的方式获得更高精度的分割掩码。 -
最后,为了在
SAM
和
MLLM
之间建立联系,一种简单的方法是使
MLLM
生成
SAM
的提示点。利用
LLM
的对话能力,主动要求
MLLM
获取
SAM
的有效提示点。
SAM4MLLM
解决了
RES
问题,使得
MLLMs
能够学习像素级的位置信息。将详细的视觉信息与大型语言模型强大的表达能力以统一的基于语言的方式结合起来,而在学习中没有额外的计算开销。
SAM4MLLM
SAM4MLLM
编码分割掩码为
SAM
提示
SAM
现有的用于分割的
MLLMs
依赖于模型架构的专门设计、分割特定的
token
和异构损失函数来预测对象掩码。而
SAM4MLLM
利用了
SAM
的特点,将少量文本提示
token
(边界框加上几个指示它们是否位于对象区域的点)转换为高质量的连续分割掩码。
SAM4MLLM
使用在边界框内采样的点作为离散提示。具体而言,使用一个边界框
\(Prompt_B \in \mathbb{N}^4\)
和
\(\mathcal{K}\)
个点来编码任意形状的掩码。
\(\mathcal{K}\)
个点的提示,每个点包含三个值:
\(x\)
坐标、
\(y\)
坐标以及它是否在掩码上,编码为
\(Prompt_P \in \mathbb{N}^{\mathcal{K} \times 3}\)
。
通过将连续分割掩码编码为离散的
SAM
提示,避免了添加任何
token
或改变模型结构,同时仅使用文本自回归交叉熵损失进行训练。这种方法与语言模型的原始训练模式一致,使得
MLLMs
能够理解像素级信息,并促进未来的模型扩展变得更加容易。
使用
MLLM
提示
SAM
MLLM
SAM
为了将
SAM
以统一的方式纳入
MLLM
,一个主要问题在于获取
SAM
的提示点,包括在物体掩码区域内的正点(
inside
)和在外部的负点(
outside
)。为此,提出了两种解决方案:提示点生成(
Prompt-Point Generation
,
PPG
)和主动查询提示点(
Proactive Query of Prompt-Points
,
PQPP
)。
PPG
直接采用
MLLM
来生成提示点和边界框,但同时生成多个点的学习将面临挑战,因此仅使用了少量提示点。
PQPP
则利用了
MLLM
的对话能力,首先询问一个粗略的边界框,然后通过问答的方式在边界框内探测多个感兴趣的点以提示
SAM
。
-
SAM4MLLM-PPG
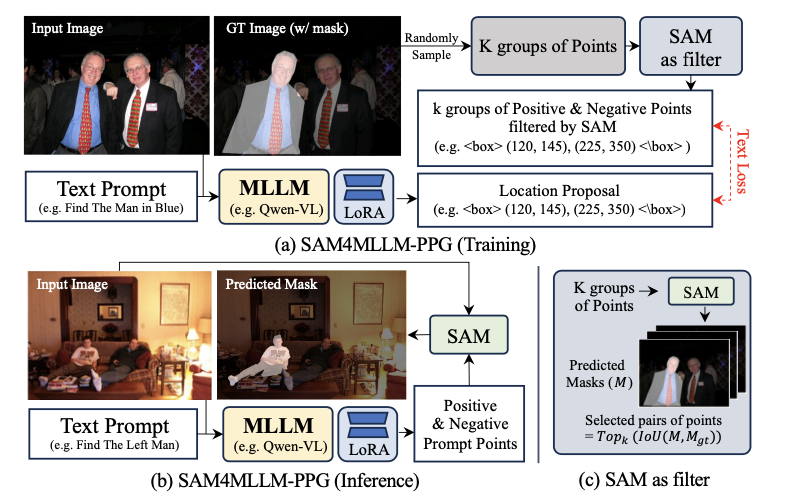
PPG
采用了一种能够同时接受文本提示和图像输入的
MLLM
。为了使
MLLM
与分割任务对齐,使用了参数高效的微调技术
LoRA
,从而基于包含图像-文本对和真实掩码的
RES
数据集进行模型训练。
LoRA
输出位置提示,包括边界框
\(Prompt_B \in \mathbb{N}^4\)
和
\(k\)
组正点和负点
\(Prompt_P \in \mathbb{N}^{(n_1+n_2)k \times 3}\)
,如图 (
a
) 所示,其中一组包含
\(n_1\)
个正点和
\(n_2\)
个负点(
\(n_1=2, n_2=1\)
)。
为了向
LoRA
提供位置监督,在训练阶段根据物体掩码随机采样
\(K\)
组点(
\(K>k\)
),然后将这些提示发送给
SAM
。对于每一组,
SAM
输出分割结果。过滤掉与真实掩码相比
IoU
较低的提示,仅保留前
\(k\)
组(如图 (
c
) 所示)。在该实现中,仅需要文本损失(自回归交叉熵损失)。
\(K\)
通常为
64
,
\(k=1\)
。
在推理阶段,
LoRA
直接输出发送给
SAM
进行分割的点,如图 (
b
) 所示。
-
SAM4MLLM-PQPP
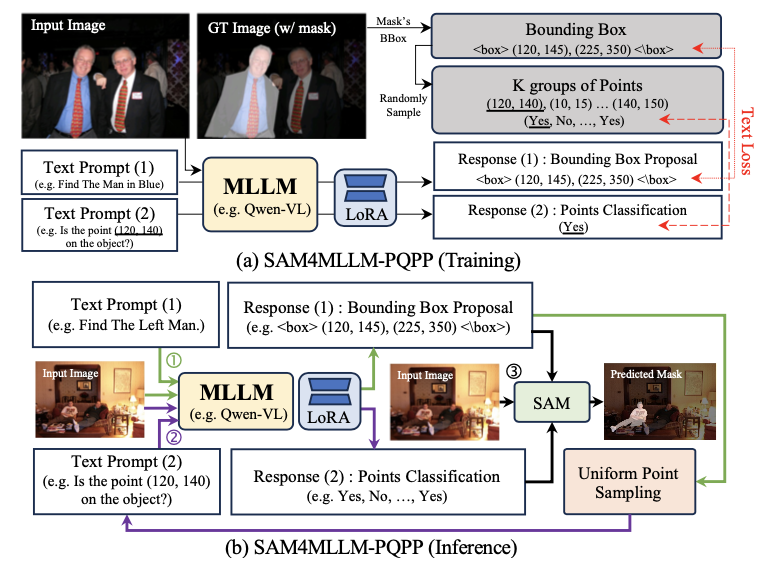
PQPP
利用
MLLM
的查询-响应能力,而不是直接生成提示。对提示点进行采样,并主动询问
MLLM
这些点是否在掩码内(或外)。在训练阶段,根据真实掩码随机采样一个边界框和
\(K\)
组点,并进行两轮对话。在对话的第一轮中,
LoRA
响应一个边界框。在第二轮中,对于每个
\((n_1+n_2)K\)
个点,
LoRA
在训练期间响应该点是否在掩码内(是或否)。
在推理阶段,
LoRA
在第一轮中为输入的文本查询和图像输出一个边界框。然后,在边界框内均匀采样点并在第二轮再次发送给
MLLM-LoRA
,并询问它们是否为正点(或负点),用于
SAM
进行分割。通常将网格大小设置为
\(5\times 5\)
。为了在发送到
SAM
之前提供高质量的提示点,低置信度的点将被移除。
RES训练
为了使基础
MLLM
与
RES
任务对齐,使用包含与
RES
相关示例的三个数据集来指导模型朝目标前进。其中两个(
RES
数据集和
gRefCOCO
数据集)包含具有真实掩码的
RES
数据,第三个(
VQA
)是一个没有掩码的视觉对话数据集,用于进一步增强联合视觉-语言理解的总体能力。
在训练期间,为了保持
MLLM
在图像上的泛化能力,冻结了大部分网络参数,只调整了
MLLM
的视觉重采样器和
LoRA
适配器。
对于上述提到的所有数据集,我们在训练过程中不使用数据增强,因为翻转和/或裁剪可能会改变图像中物体的相对位置或关系。
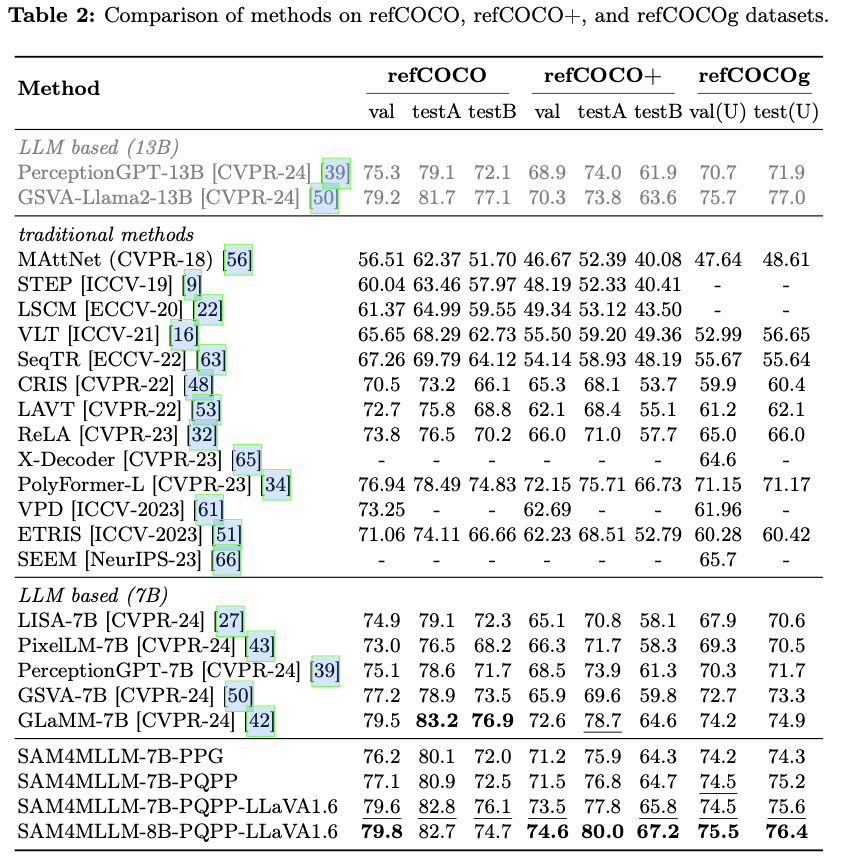
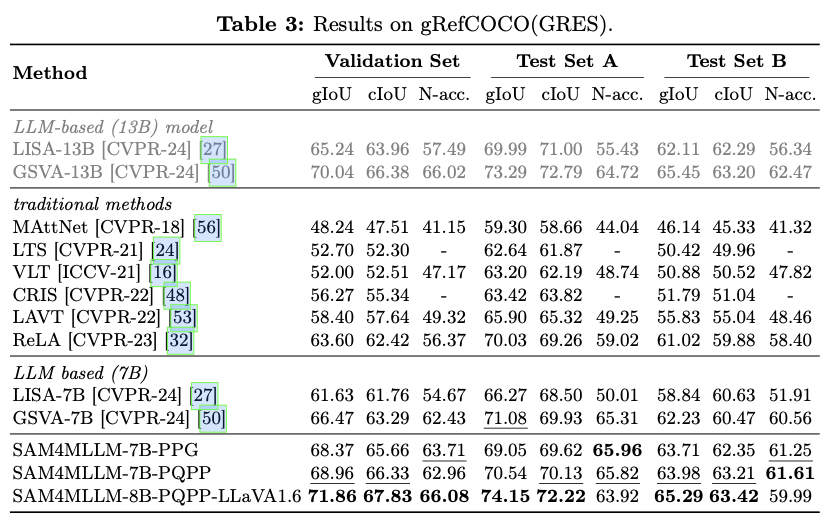
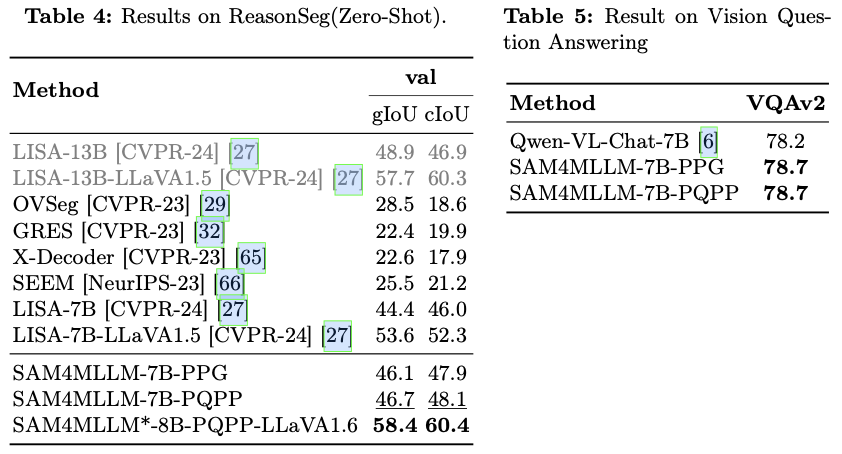
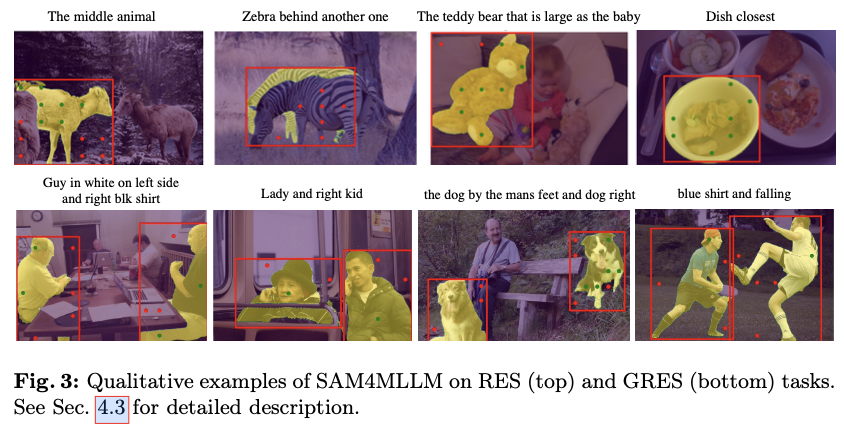
主要实验
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

- CC加速器免费下载《模拟农场25》上线重温儿时农场梦 2024-11-14
- 《原神》5.1百货奇货兑换素材汇总 2024-11-14
- 拔掉一根白发会长十根白发吗 2024-11-14
- 《勇者斗恶龙3重制版》中角色能力属性详解 2024-11-14
- 世界之外问雪世界之间活动攻略 2024-11-14
- 蚂蚁庄园最新答案:易过敏体质人群更适合哪种材质的被子? 2024-11-14
- 三国志战略版11月13日更新内容详解 2024-11-14
- 《龙腾世纪:影障守护者》影障逾越者的困境任务攻略分享 2024-11-13



























