

现在 Llama 具备视觉能力并可以在你的设备上运行 - 欢迎使用 Llama 3.2
发布: 更新时间:2024-10-16 10:09:50
Llama 3.2 来了!今天,我们欢迎 Llama 系列的下一个版本加入 Hugging Face。这次,我们很高兴与 Meta 合作发布多模态和小型模型。在 Hub 上提供了十个开源模型 (5 个多模态模型和 5 个仅文本模型)。
Llama 3.2 Vision 有两种尺寸: 11B 适用于在消费级 GPU 上的高效部署和开发,90B 适用于大规模应用。两种版本都有基础版和指令微调版。除了这四个多模态模型外,Meta 还发布了支持视觉的新版 Llama Guard。Llama Guard 3 是一个安全模型,可以分类模型输入和生成内容,包括检测有害的多模态提示或助手响应。
Llama 3.2 还包括可以在设备上运行的小型仅文本语言模型。它们有两种新大小 (1B 和 3B),并提供基础版和指令版,具有强大的能力。还有一个小型 1B 版本的 Llama Guard,可以与这些或更大的文本模型一起部署在生产用例中。
在发布的功能和集成中,我们有:
- Hub 上的模型检查点
- Hugging Face Transformers 和 TGI 对视觉模型的集成
- 在 Google Cloud、Amazon SageMaker 和 DELL 企业中心的推理与部署集成
-
使用
transformers?
和
TRL
在单个 GPU 上微调 Llama 3.2 11B 视觉模型
什么是 Llama3.2 Vision 模型?
Llama 3.2 Vision 是 Meta 发布的最强大的开源多模态模型。它具有出色的视觉理解和推理能力,可以用于完成各种任务,包括视觉推理与定位、文档问答和图像 - 文本检索。思维链 (Chain of Thought, CoT) 答案通常非常好,这使得视觉推理特别强大。
Llama 3.2 Vision 可以处理文本和图像,也可以仅处理文本。对于图像 - 文本提示,模型可以接受英文输入,而对于仅文本提示,模型可以处理多种语言。在仅文本模式下,支持的完整语言列表包括英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。
这些模型的架构基于 Llama 3.1 LLM 与视觉塔和图像适配器的组合。用于 Llama 3.2 11B Vision 的文本模型是 Llama 3.1 8B,而 Llama 3.2 90B Vision 则使用 Llama 3.1 70B。根据我们的了解,文本模型在视觉模型训练期间是冻结的,以保持仅文本的性能。
下面是一些来自 11B 指令调优模型的推理示例,展示了真实世界知识、文档推理和信息图理解能力。

|
这张图片位于哪里?附近还有哪些景点? 图片描绘的是泰国曼谷的大皇宫。大皇宫是一个建筑群,曾作为暹罗国王的官方住所,并作为政府的行政中心达 150 年之久。它是曼谷最受欢迎的旅游景点之一,是任何访问该市的人必去之地。 大皇宫附近的一些其他景点包括: |
|
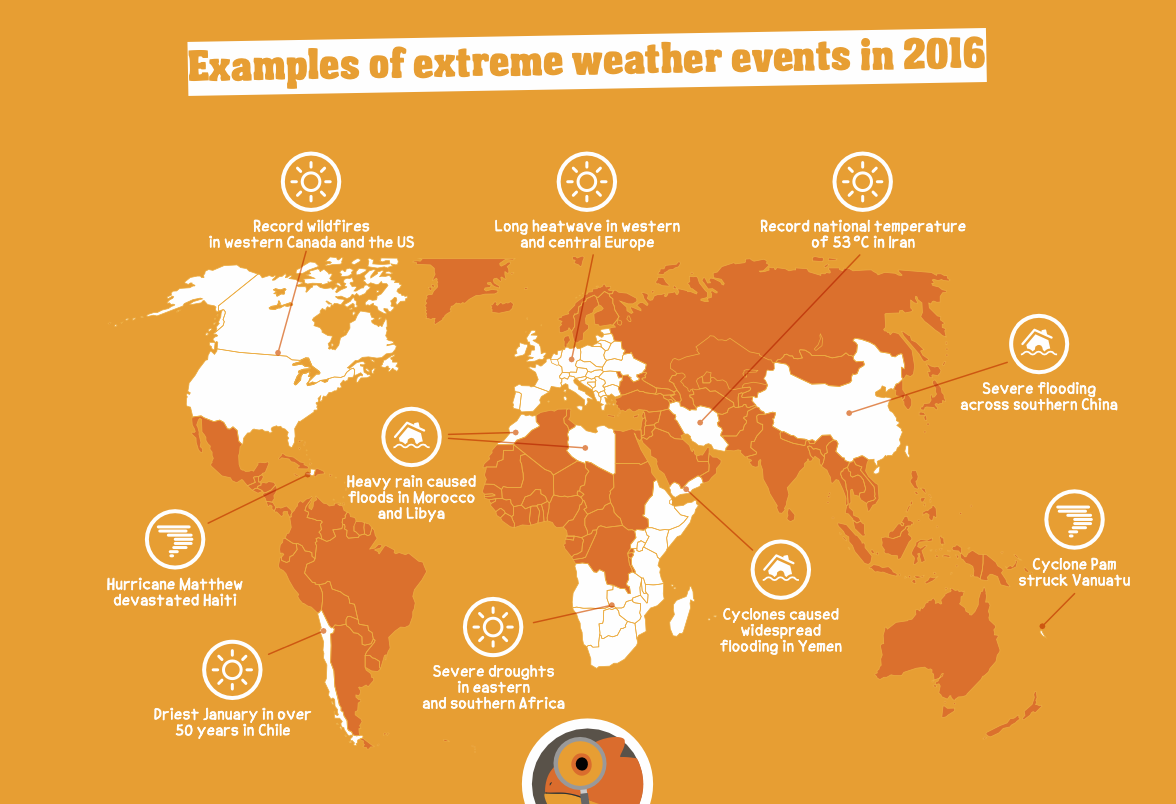
根据这张图表,干旱发生在什么地方? 2016 年干旱区域: 根据图表,2016 年发生干旱的地区有两个: * 东非和南非: 该地区经历了严重的干旱。 * 智利: 智利在 1 月份经历了 50 多年来最干燥的天气。这些地区在那段时间面临严重的水资源短缺问题。 |

|
从发票日期到到期日期需要多长时间?请简洁明了。 发票日期: 2019 年 2 月 11 日 到期日期: 2019 年 2 月 26 日 时间差计算: 2019 年 2 月 26 日 - 2019 年 2 月 11 日 = 15 天 发票日期与到期日期之间的时间差为**15 天**。 |
Vision 模型的上下文长度为 128k 个 token,这允许包含图像的多轮对话。然而,该模型在关注单一图像时效果最佳,因此
transformers
实现仅关注输入中的最后一张图像。这可以保持质量并节省内存。
11B 基础模型支持 448 的分块尺寸,而指令微调版本和 90B 模型都使用 560 的分块尺寸。这些模型在一个包含 60 亿图文对的海量数据集上进行了训练,数据来源非常多样化。这使得它们成为下游任务微调的极佳候选模型。下表展示了 11B、90B 模型及其指令微调版本在一些基准测试中的表现,数据来自 Meta。请参阅模型卡片以获取更多基准测试和详细信息。
| 模型 | 11B | 11B (指令微调) | 90B | 90B (指令微调) | 指标 |
|---|---|---|---|---|---|
| MMMU (val) | 41.7 | 50.7 (CoT) | 49.3 (zero-shot) | 60.3 (CoT) | Micro Average Accuracy |
| VQAv2 | 66.8 (val) | 75.2 (test) | 73.6 (val) | 78.1 (test) | Accuracy |
| DocVQA | 62.3 (val) | 88.4 (test) | 70.7 (val) | 90.1 (test) | ANLS |
| AI2D | 62.4 | 91.1 | 75.3 | 92.3 | Accuracy |
我们预计这些模型的文本能力将与 8B 和 70B 的 Llama 3.1 模型相当,因为我们的理解是文本模型在 Vision 模型训练期间是冻结的。因此,文本基准测试应该与 8B 和 70B 一致。
Llama 3.2 许可证变更。对不起,欧盟 ?

关于许可条款,Llama 3.2 的许可与 Llama 3.1 非常相似,唯一的关键区别在于可接受使用政策: 任何居住在欧盟的个人或在欧盟有主要营业地点的公司不被授予使用 Llama 3.2 中包含的多模态模型的许可权。这一限制不适用于集成了任何此类多模态模型的产品或服务的最终用户,因此人们仍然可以构建全球产品与视觉变体。
有关完整详情,请务必阅读
官方许可证
和
可接受的使用政策
。
Llama 3.2 1B 和 3B 有什么特别之处?
Llama 3.2 系列包括 1B 和 3B 文本模型。这些模型旨在用于设备上的使用案例,如提示重写、多语言知识检索、摘要任务、工具使用和本地运行的助手。它们在这些规模上超过了许多可用的开放访问模型,并与大得多的模型竞争。在后面的部分中,我们将展示如何离线运行这些模型。
这些模型遵循与 Llama 3.1 相同的架构。它们使用高达 9 万亿个 token 进行训练,并仍然支持长上下文长度的 128k 个 token。模型是多语言的,支持英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。
还有一个新的 Llama Guard 小版本,Llama Guard 3 1B,可以与这些模型一起部署,以评估多轮对话中最后一次用户或助手的响应。它使用一组预定义的类别 (在此版本中新增),可以根据开发者的用例进行自定义或排除。有关使用 Llama Guard 的更多详细信息,请参考模型卡。
额外提示: Llama 3.2 接触了比上述 8 种语言更广泛的语言集合。鼓励开发者针对特定语言用例微调 Llama 3.2 模型。
我们通过 Open LLM Leaderboard 评估套件对基础模型进行了测试,而指令模型则在三个流行的基准上进行了评估,这些基准衡量遵循指令的能力,并与 LMSYS Chatbot Arena 高度相关:
IFEval
、
AlpacaEval
和
MixEval-Hard
。以下是基础模型的结果,其中包括 Llama-3.1-8B 作为参考:
| 模型 | BBH | MATH Lvl 5 | GPQA | MUSR | MMLU-PRO | 平均 |
|---|---|---|---|---|---|---|
| Meta-Llama-3.2-1B | 4.37 | 0.23 | 0.00 | 2.56 | 2.26 | 1.88 |
| Meta-Llama-3.2-3B | 14.73 | 1.28 | 4.03 | 3.39 | 16.57 | 8.00 |
| Meta-Llama-3.1-8B | 25.29 | 4.61 | 6.15 | 8.98 | 24.95 | 14.00 |
以下是指令模型的结果,以Llama-3.1-8B-Instruct 作为参考:
| 模型 | AlpacaEval (LC) | IFEval | MixEval-Hard | 平均 |
|---|---|---|---|---|
| Meta-Llama-3.2-1B-Instruct | 7.17 | 58.92 | 26.10 | 30.73 |
| Meta-Llama-3.2-3B-Instruct | 20.88 | 77.01 | 31.80 | 43.23 |
| Meta-Llama-3.1-8B-Instruct | 25.74 | 76.49 | 44.10 | 48.78 |
值得注意的是,3B 模型在 IFEval 上的表现与 8B 模型相当!这使得该模型非常适合代理应用,在这些应用中,遵循指令对于提高可靠性至关重要。这个高 IFEval 分数对于这个规模的模型来说非常令人印象深刻。
1B 和 3B 的指令调优模型均支持工具使用。用户在 0-shot 环境中指定工具 (模型之前没有关于开发者将使用的工具的信息)。因此,Llama 3.1 模型中包含的内置工具 (
brave_search
和
wolfram_alpha
) 不再可用。
由于其体积小,这些小模型可以作为更大模型的助手,执行
辅助生成
(也称为推测解码)。
这里
是一个使用 Llama 3.2 1B 模型作为 Llama 3.1 8B 模型助手的示例。有关离线使用案例,请查看后面的设备上运行部分。
演示
你可以在以下演示中体验这三种指令模型:
- Gradio 空间中的 Llama 3.2 11B 视觉指令
- Gradio 驱动的空间中的 Llama 3.2 3B
- Llama 3.2 3B 在 WebGPU 上运行
使用 Hugging Face Transformers
仅文本检查点具有与之前版本相同的架构,因此无需更新你的环境。然而,由于新的架构,Llama 3.2 Vision 需要更新 Transformers。请确保将你的安装升级到 4.45.0 或更高版本。
pip install "transformers>=4.45.0" --upgrade
升级后,你可以使用新的 Llama 3.2 模型,并利用 Hugging Face 生态系统的所有工具。
Llama 3.2 1B 和 3B 语言模型
你可以仅用几行代码通过 Transformers 运行 1B 和 3B 文本模型检查点。模型检查点以
bfloat16
精度上传,但你也可以使用 float16 或量化权重。内存要求取决于模型大小和权重精度。以下是一个表格,显示使用不同配置进行推理时所需的大致内存:
| Model Size | BF16/FP16 | FP8 | INT4 |
|---|---|---|---|
| 3B | 6.5 GB | 3.2 GB | 1.75 GB |
| 1B | 2.5 GB | 1.25 GB | 0.75 GB |
from transformers import pipeline
import torch
model_id = "meta-llama/Llama-3.2-3B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "user", "content": "Who are you? Please, answer in pirate-speak."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
response = outputs[0]["generated_text"][-1]["content"]
print(response)
# Arrrr, me hearty! Yer lookin' fer a bit o' information about meself, eh? Alright then, matey! I be a language-generatin' swashbuckler, a digital buccaneer with a penchant fer spinnin' words into gold doubloons o' knowledge! Me name be... (dramatic pause)...Assistant! Aye, that be me name, and I be here to help ye navigate the seven seas o' questions and find the hidden treasure o' answers! So hoist the sails and set course fer adventure, me hearty! What be yer first question?
一些细节:
-
我们使用
bfloat16
加载模型。如上所述,这是 Meta 发布的原始检查点所使用的类型,因此建议以确保最佳精度或进行评估。根据你的硬件,float16 可能会更快。 - 默认情况下,transformers 使用与原始 Meta 代码库相同的采样参数 (temperature=0.6 和 top_p=0.9)。我们尚未进行广泛测试,请随意探索!
Llama 3.2 视觉模型
Vision 模型更大,因此比小型文本模型需要更多的内存来运行。作为参考,11B Vision 模型在 4 位模式下进行推理大约需要 10 GB 的 GPU RAM。
使用指令调优的 Llama 视觉模型进行推理的最简单方法是使用内置的聊天模板。输入具有
user
和
assistant
角色,以指示对话的轮次。与文本模型的一个区别是不支持系统角色。用户轮次可以包括图像 - 文本或仅文本输入。要指示输入包含图像,请在输入的内容部分添加
{"type": "image"}
,然后将图像数据传递给
processor
:
import requests
import torch
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device="cuda",
)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Can you please describe this image in just one sentence?"}
]}
]
input_text = processor.apply_chat_template(
messages, add_generation_prompt=True,
)
inputs = processor(
image, input_text, return_tensors="pt"
).to(model.device)
output = model.generate(**inputs, max_new_tokens=70)
print(processor.decode(output[0][inputs["input_ids"].shape[-1]:]))
## The image depicts a rabbit dressed in a blue coat and brown vest, standing on a dirt road in front of a stone house.
你可以继续关于图像的对话。请记住,如果你在新用户轮次中提供新图像,模型将从那时起引用新图像。你不能同时查询两幅不同的图像。这是继续之前对话的一个示例,我们在对话中添加助手轮次,并询问一些更多的细节:
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Can you please describe this image in just one sentence?"}
]},
{"role": "assistant", "content": "The image depicts a rabbit dressed in a blue coat and brown vest, standing on a dirt road in front of a stone house."},
{"role": "user", "content": "What is in the background?"}
]
input_text = processor.apply_chat_template(
messages,
add_generation_prompt=True,
)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=70)
print(processor.decode(output[0][inputs["input_ids"].shape[-1]:]))
这是我们得到的回复:
In the background, there is a stone house with a thatched roof, a dirt road, a field of flowers, and rolling hills.
你还可以使用
bitsandbytes
库自动量化模型,以 8-bit 或甚至 4-bit 模式加载。以下是如何在 4-bit 模式下加载生成管道的示例:
import torch
from transformers import MllamaForConditionalGeneration, AutoProcessor
+from transformers import BitsAndBytesConfig
+bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.bfloat16
)
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
- torch_dtype=torch.bfloat16,
- device="cuda",
+ quantization_config=bnb_config,
)
然后,你可以应用聊天模板,使用
processor
,并像以前一样调用模型。
设备端部署
你可以直接在设备的 CPU/GPU/浏览器上运行 Llama 3.2 1B 和 3B,使用多个开源库,如下所示。
Llama.cpp & Llama-cpp-python
Llama.cpp
是进行跨平台设备上机器学习推理的首选框架。我们为 1B 和 3B 模型提供了 4-bit 和 8-bit 的量化权重。我们希望社区能够采用这些模型,并创建其他量化和微调。你可以在
这里
找到所有量化的 Llama 3.2 模型。
以下是如何直接使用 llama.cpp 运行这些检查点的方法。
通过 brew 安装 llama.cpp (适用于 Mac 和 Linux)。
brew install llama.cpp
你可以使用 CLI 运行单次生成或调用兼容 Open AI 消息规范的 llama.cpp 服务器。
你可以使用如下命令运行 CLI:
llama-cli --hf-repo hugging-quants/Llama-3.2-3B-Instruct-Q8_0-GGUF --hf-file llama-3.2-3b-instruct-q8_0.gguf -p " 生命和宇宙的意义是 "
你可以这样启动服务器:
llama-server --hf-repo hugging-quants/Llama-3.2-3B-Instruct-Q8_0-GGUF --hf-file llama-3.2-3b-instruct-q8_0.gguf -c 2048
你还可以使用
llama-cpp-python
在 Python 中以编程方式访问这些模型。
from llama_cpp import Llama
llm = Llama.from_pretrained(
repo_id="hugging-quants/Llama-3.2-3B-Instruct-Q8_0-GGUF",
filename="*q8_0.gguf",
)
llm.create_chat_completion(
messages = [
{
"role": "user",
"content": "What is the capital of France?"
}
]
)
Transformers.js
你甚至可以在浏览器 (或任何 JavaScript 运行时,如 Node.js、Deno 或 Bun) 中使用
Transformers.js
运行 Llama 3.2。你可以在 Hub 上找到
ONNX 模型
。如果你还没有安装该库,可以通过
NPM
使用以下命令安装:
npm i @huggingface/transformers
然后,你可以按照以下方式运行模型:
import { pipeline } from "@huggingface/transformers";
// Create a text generation pipeline
const generator = await pipeline("text-generation", "onnx-community/Llama-3.2-1B-Instruct");
// Define the list of messages
const messages = [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Tell me a joke." },
];
// Generate a response
const output = await generator(messages, { max_new_tokens: 128 });
console.log(output[0].generated_text.at(-1).content);
Here's a joke for you:
What do you call a fake noodle?
An impasta!
I hope that made you laugh! Do you want to hear another one?
微调 Llama 3.2
TRL 支持直接对 Llama 3.2 文本模型进行聊天和微调:
# Chat
trl chat --model_name_or_path meta-llama/Llama-3.2-3B
# Fine-tune
trl sft --model_name_or_path meta-llama/Llama-3.2-3B \
--dataset_name HuggingFaceH4/no_robots \
--output_dir Llama-3.2-3B-Instruct-sft \
--gradient_checkpointing
TRL 还支持使用
这个脚本
微调 Llama 3.2 Vision。
# Tested on 8x H100 GPUs
accelerate launch --config_file=examples/accelerate_configs/deepspeed_zero3.yaml \
examples/scripts/sft_vlm.py \
--dataset_name HuggingFaceH4/llava-instruct-mix-vsft \
--model_name_or_path meta-llama/Llama-3.2-11B-Vision-Instruct \
--per_device_train_batch_size 8 \
--gradient_accumulation_steps 8 \
--output_dir Llama-3.2-11B-Vision-Instruct-sft \
--bf16 \
--torch_dtype bfloat16 \
--gradient_checkpointing
你还可以查看
笔记本
,了解如何使用 Transformers 和 PEFT 进行 LoRA 微调。
Hugging Face 合作伙伴集成
我们目前正在与 AWS、Google Cloud、Microsoft Azure 和 DELL 的合作伙伴合作,正在将 Llama 3.2 11B 和 90B 模型添加到 Amazon SageMaker、Google Kubernetes Engine、Vertex AI Model Catalog、Azure AI Studio 和 DELL Enterprise Hub 中。我们会在这些容器可用时更新本节内容,你可以订阅
Hugging Squad
获取电子邮件更新。
额外资源
- Hub 上的模型
- Hugging Face Llama Recipes
- Open LLM Leaderboard
- Meta Blog
- 评估数据集
鸣谢
没有成千上万社区成员的贡献,这种模型的发布以及生态系统中的支持和评估将无法实现,他们为 transformers、text-generation-inference、vllm、pytorch、LM Eval Harness 以及其他众多项目作出了贡献。特别感谢 VLLM 团队的测试和问题报告支持。这次发布的顺利进行离不开 Clémentine、Alina、Elie 和 Loubna 对 LLM 评估的支持,Nicolas Patry、Olivier Dehaene 和 Daniël de Kok 对文本生成推理的贡献; Lysandre、Arthur、Pavel、Edward Beeching、Amy、Benjamin、Joao、Pablo、Raushan Turganbay、Matthew Carrigan 和 Joshua Lochner 对 transformers、transformers.js、TRL 和 PEFT 的支持; Nathan Sarrazin 和 Victor 让 Llama 3.2 在 Hugging Chat 上可用; Brigitte Tousignant 和 Florent Daudens 的沟通支持; Julien、Simon、Pierric、Eliott、Lucain、Alvaro、Caleb 和 Mishig 来自 Hub 团队的开发和功能发布支持。
特别感谢 Meta 团队发布 Llama 3.2 并使其开放给 AI 社区!
原文链接:
https://hf.co/blog/llama32原文作者: Merve Noyan, Philipp Schmid, Omar Sanseviero, Vaibhav Srivastav, Lewis Tunstall, Aritra Roy Gosthipaty, Pedro Cuenca
译者: cheninwang, roseking
- 《暗喻幻想》怎么召唤加莉卡 2024-10-16
- 《何处》回响1第一关全点位月亮位置分享 2024-10-16
- 奇幻魔法,逻辑盛宴!网易狼人杀xLAL逻辑与谎言联动赛事开启 2024-10-16
- 现在 Llama 具备视觉能力并可以在你的设备上运行 - 欢迎使用 Llama 3.2 2024-10-16
- 这个世界就是一个乙游大世界!每个人都是play的一环! 2024-10-16
- 重返未来1999新版本双重解析活动全新开启 2024-10-16
- 2024《淘宝》双11红包攻略 2024-10-15
- 《无尽梦回》开局流程和配队推荐 2024-10-15



























