

如何使用C#爬取动态内容网站
发布: 更新时间:2024-09-28 09:50:54
动态内容网站使用 JavaScript 脚本动态检索和渲染数据,爬取信息时需要模拟浏览器行为,否则获取到的源码基本是空的。爬取步骤如下:
使用
Selenium
获取渲染后的 HTML 文档
使用
HtmlAgilityPack
解析 HTML 文档
新建项目,安装需要的库:
Selenium.WebDriver
HtmlAgilityPack
获取 HTML 文档
需要注意的主要是以下2点:
- 设置浏览器启动参数:无头模式、禁用GPU加速、设置启动时窗口大小
- 等待页面动态加载完成:等待5秒钟,设置一个合适的时间即可
private static string GetHtml(string url)
{
ChromeOptions options = new ChromeOptions();
// 不显示浏览器
options.AddArgument("--headless");
// GPU加速可能会导致Chrome出现黑屏及CPU占用率过高
options.AddArgument("--nogpu");
// 设置chrome启动时size大小
options.AddArgument("--window-size=10,10");
using (var driver = new ChromeDriver(options))
{
try
{
driver.Manage().Window.Minimize();
driver.Navigate().GoToUrl(url);
// 等待页面动态加载完成
Thread.Sleep(5000);
// 返回页面源码
return driver.PageSource;
}
catch (NoSuchElementException)
{
Console.WriteLine("找不到该元素");
return string.Empty;
}
}
}
解析 HTML 文档
这里以B站为例,爬取B站UP主主页上的视频信息,如视频的标题、链接、封面。
先定义一个类来保存信息:
class VideoInfo
{
public string Title { get; set; }
public string Href { get; set; }
public string ImgUrl { get; set; }
}
定义解析函数,返回视频信息列表:
private static List<VideoInfo> GetVideoInfos(string url)
{
List<VideoInfo> videoInfos = new List<VideoInfo>();
// 加载文档
var html = GetHtml(url);
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(html);
// 解析文档,先定位到视频列表标签
var xpath = "/html/body/div[2]/div[4]/div/div/div[1]/div[2]/div/div";
var htmlNodes = htmlDoc.DocumentNode.SelectNodes(xpath);
// 循环解析它的子节点视频信息
foreach (var node in htmlNodes)
{
var titleNode = node.SelectSingleNode("a[2]");
var imgNode = node.SelectSingleNode("a[1]/div[1]/picture/source[1]");
var title = titleNode.InnerText;
var href = titleNode.Attributes["href"].Value.Trim('/');
var imgUrl = imgNode.Attributes["srcset"].Value.Split('@')[0].Trim('/');
videoInfos.Add(new VideoInfo
{
Title = title,
Href = href,
ImgUrl = imgUrl
});
}
return videoInfos;
}
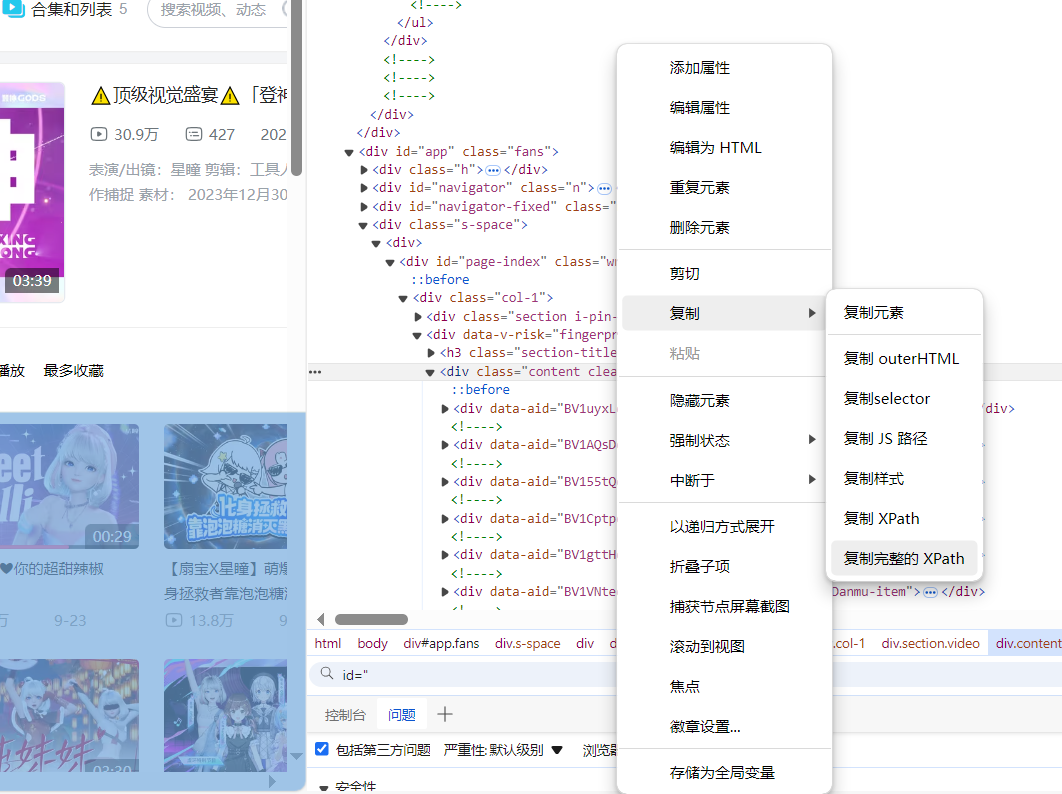
视频列表标签的
XPath
路径是通过浏览器调试工具,在指定标签上右键
复制完整的XPath
得到:
分析代码中的
node
节点时,html文本格式可能很乱,可以通过在线
HTML 代码格式化
工具格式后再进行分析。
测试
以B站UP主
星瞳_Official
为例,爬取视频信息:
static void Main(string[] args)
{
var url = @"https://space.bilibili.com/401315430";
var videoInfos = GetVideoInfos(url);
foreach (var videoInfo in videoInfos)
{
Console.WriteLine(videoInfo.Title);
Console.WriteLine(videoInfo.Href);
Console.WriteLine(videoInfo.ImgUrl);
Console.WriteLine();
}
Console.ReadKey();
}
结果如下:
等一下,好妹妹
www.bilibili.com/video/BV1uyxLeJEM9
i0.hdslb.com/bfs/archive/46a15065d1b6722a04696ffaaa2235287ceaa452.jpg
一口一个?你的超甜辣椒
www.bilibili.com/video/BV1AQsDeiEn1
i0.hdslb.com/bfs/archive/d93d47d67323ee284483e963ffed34fb9884cf61.jpg
这里只是演示爬取动态页面的方法,
如果想获取B站UP主的视频信息,建议直接使用 API 请求数据
。
参考文章
- 使用 C#语言进行网页抓取的终极指南
- C# 写个小爬虫,实现爬取js加载后的网页
- Html Agility Pack 文档
- [ 长期更新 ] C# Selenium 常用操作代码
相关阅读
- 《刀剑江湖路》佳人侠梦支线结局一,沈梦秋入队全流程攻略 2024-10-01
- 《无限试驾:太阳王冠》从英雄到零成就攻略分享 2024-10-01
- 《凶影疑云》好事之徒成就攻略分享 2024-10-01
- 西普大陆击败费尔斯困难模式攻略 2024-10-01
- 恋与制作人国庆节福利攻略 2024-10-01
- 《王权与自由》国际服汉化工具下载,《王权与自由》国际服一键汉化工具分享 2024-09-30
- 《WinkStudio》修复画质方法 2024-09-30
- 海水涨潮几乎淹没不到的地带是 2024-09-30










文章排行

















