

【Flink入门修炼】2-3 Flink Checkpoint 原理机制
发布: 更新时间:2024-04-26 08:52:06
如果让你来做一个有状态流式应用的故障恢复,你会如何来做呢?
单机和多机会遇到什么不同的问题?
Flink Checkpoint 是做什么用的?原理是什么?
一、什么是 Checkpoint?
Checkpoint 是对当前运行状态的完整记录。程序重启后能从 Checkpoint 中恢复出输入数据读取到哪了,各个算子原来的状态是什么,并继续运行程序。
即用于 Flink 的故障恢复。
这种机制保证了实时程序运行时,即使突然遇到异常也能够进行自我恢复。
二、如何实现 Checkpoint 功能?
如果让你来设计,对于流式应用如何做到故障恢复?
我们从最简单的单机单线程看起。
一)单机情况
同步执行,每次只处理一条数据
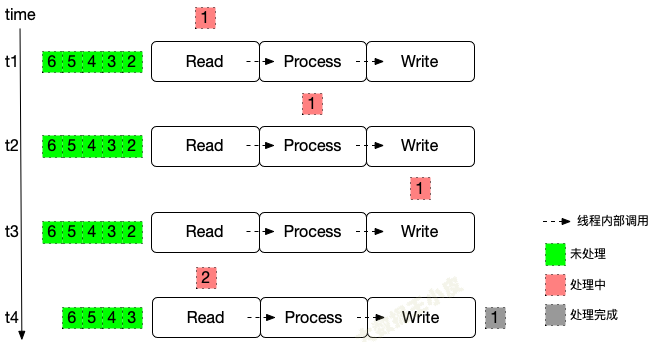
很简单,这种情况下,整个流程一次只处理一条数据。
- 数据到 Write 阶段结束,各个算子记录一次各自状态信息(如读取的 offset、中间算子的状态)
- 遇到故障需要恢复的时候,从上一次保存的状态开始执行
- 当然为了降低记录带来的开销,可以攒一批之后再记录。
同时处理多条数据
每个计算节点还是只处理一条数据,但该节点空闲就可以处理下一条数据。
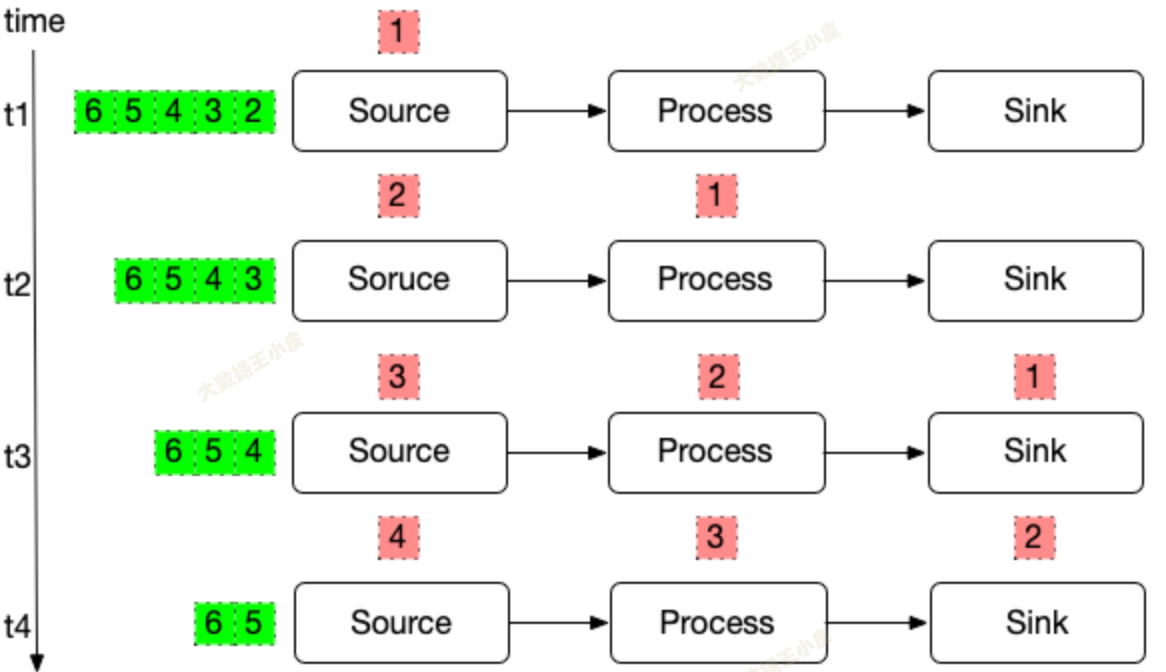
如果还按照一个数据 Write 阶段结束开始保存状态,就会出现问题:
- 前面节点的状态,在处理下一个数据时被改过了
- 从此时保存的记录恢复,前面的节点会出现重复处理的问题
-
此时被称为 -
确保数据不丢(At Least Once)
一种解决方式:
-
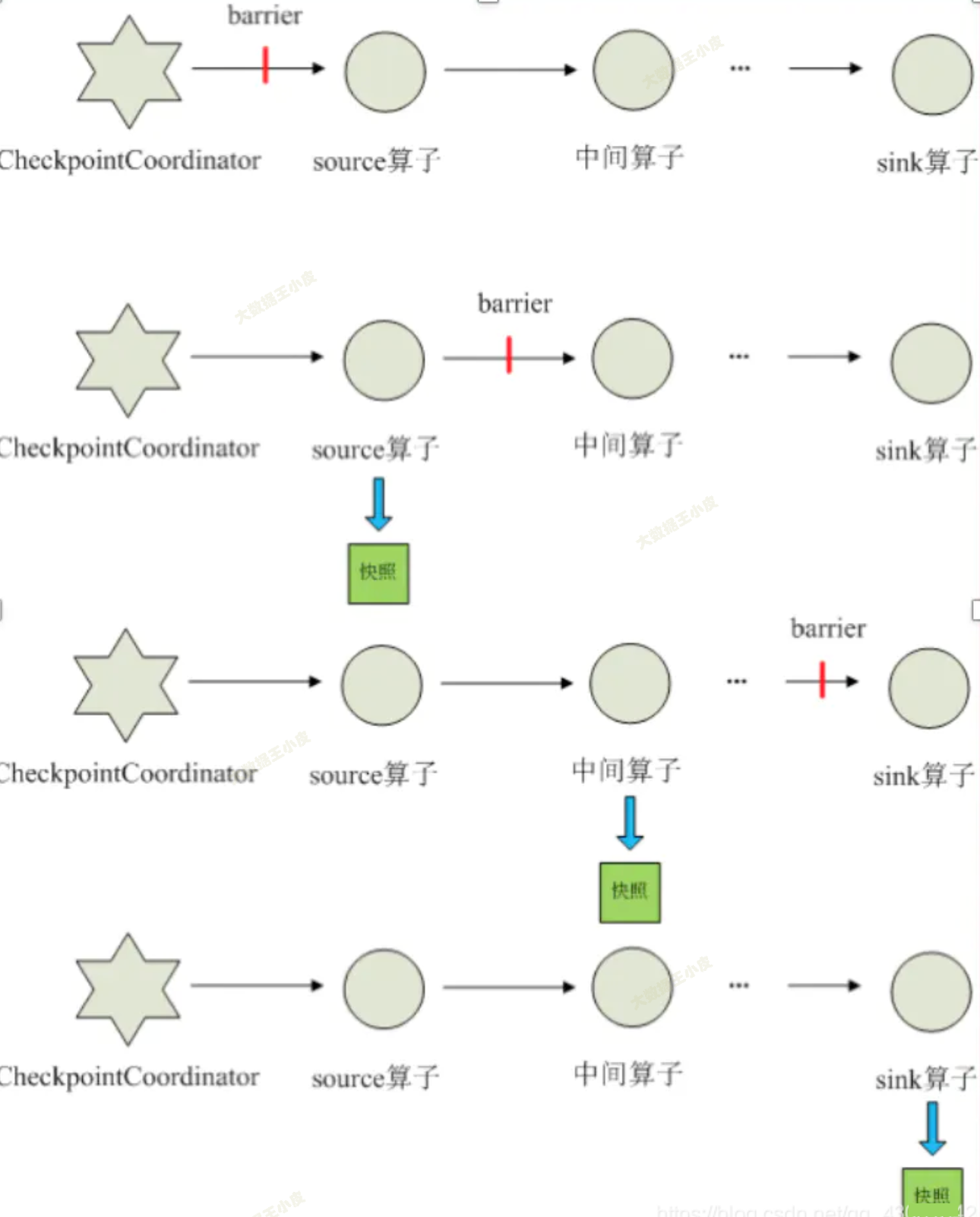
在输入数据中,定期插入一个
barrier
。 - 各算子遇到 barrier 就开始做状态保留,并且不再接收新数据的计算。
- 当前算子状态保留后,将 barrier 传递给下一个算子,并重复上面的步骤。
- 当 barrier 传递到最后一个算子,并完成状态保留后,本次状态保留完成。
这样,各个节点保存的都是相同数据节点时的状态。
故障恢复时,能做到不重复处理数据,也就是
精确一次(Exactly-once)。
但这里,你可能会发现一个问题:
- 数据已经写出了怎么办?在两个保存点之间,已经把结果写到外部了,重启后不是又把部分数据再写了一次?
这里实际是
「程序内部精确一次」
和
「端到端精确一次」
。
那么如何做到「端到端精确一次」?
- 方案一:最后一个 sink 算子不直接向外部写出,等到 barrier 来了,才把这一批数据批量写出去
-
方案二:两阶段提交。需要 sink 端支持(如 kafka)。
- 方式类似于 MySQL 的事务。
- sink 端正常向外部写出,不过输出端处于 pre-commit 状态,这些数据还不可读取
- 当 sink 端等到 barrier 时,将输出端数据变为 committed,下游输出端的数据才正式可读
不过以上方法为了做到端到端精确一次,会带来
数据延迟
问题。(因为要等 Checkpoint 做完,数据才实际可读)。
解决数据延迟有一种方案:
- 方案:幂等写入。同样一条数据,无论写入多少次对输出端看来都是一样的。(比如按照主键重复写这一条数据,并且数据本身没变化)
二)重要概念介绍
一致性级别
前面的例子中,我们提到了部分一致性级别,这里我们总结下。在流处理中,一致性可以分为 3 个级别:
-
at-most-once(最多一次)
: 这其实是没有正确性保障的委婉说法——故障发生之后,计数结果可能丢失。 -
at-least-once (至少一次)
: 这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算。 -
exactly-once (精确一次)
: 这指的是系统保证在发生故障后得到的计数结果与正确值一致。恰好处理一次是最严格的保证,也是最难实现的。
按区间分:
- 程序(Flink)内部精确一次
- 端到端精确一次
Checkpoint 中保留的是什么信息?
? 如果是你来设计,checkpoint 都需要保留哪些信息,才能让程序恢复执行?
【这里说的就是
state
】
考虑一个开发需求:单词计数。
从 kafka 中读数据,处理逻辑是将输入数据拆分成单词,有一个 map 记录各个单词的数量,最后输出。
- 从输入流中,拆分单词
- 将统计的结果放到内存中一个 Map 集合,单词做为 key,对应的数量做为 value
想要恢复的时候还能接着上次的状态来,要么就需要几个信息:
- 处理到哪条数据了
- 中间状态是啥
- 数据写出到哪条了
以及,上述信息应是针对同一条数据的。否则状态就乱了。
那么可以得到,保留的信息是:
| source | 中间算子 | sink |
|---|---|---|
| 已输入的数据(offset) | [<hello, 5>, <world, 10>, ...] | 写出到第几条了 |
三)多机多进程
随着业务的发展,单机已经不能满足需求了,开始并行分布式的处理。
读取、处理、写出,也不再是一个进程从头到尾干完,会拆分到多个机器上执行。也不再等待一条数据处理完,才处理下一条。
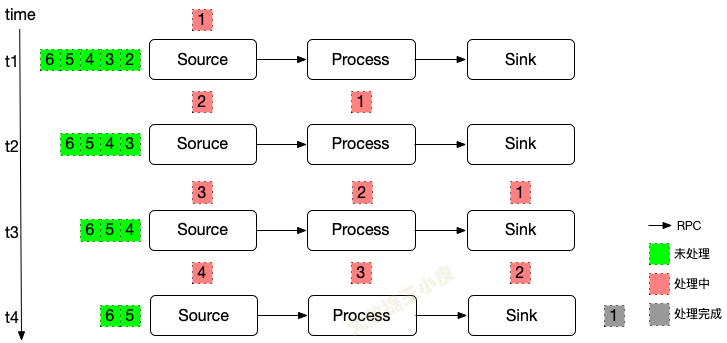
多机多线程,问题就开始变得复杂起来:
- 如何确保状态拥有精确一次的容错保证?
- 如何在分布式场景下,替多个拥有本地状态的算子产生一个全域一致的快照?
- 对于流合并,合并节点会受到多个 barrier 如何处理?
- 如何在不中断运算的前提下产生快照?
? 先思考下,如果还用单线程中 barrier 的方式来处理。会遇到什么问题,该如何解决?
处理流程
我们还是在数据流中插入 barrier。
- 到达第一个 source 节点和之前的没区别,source 节点开始保存状态(offset)
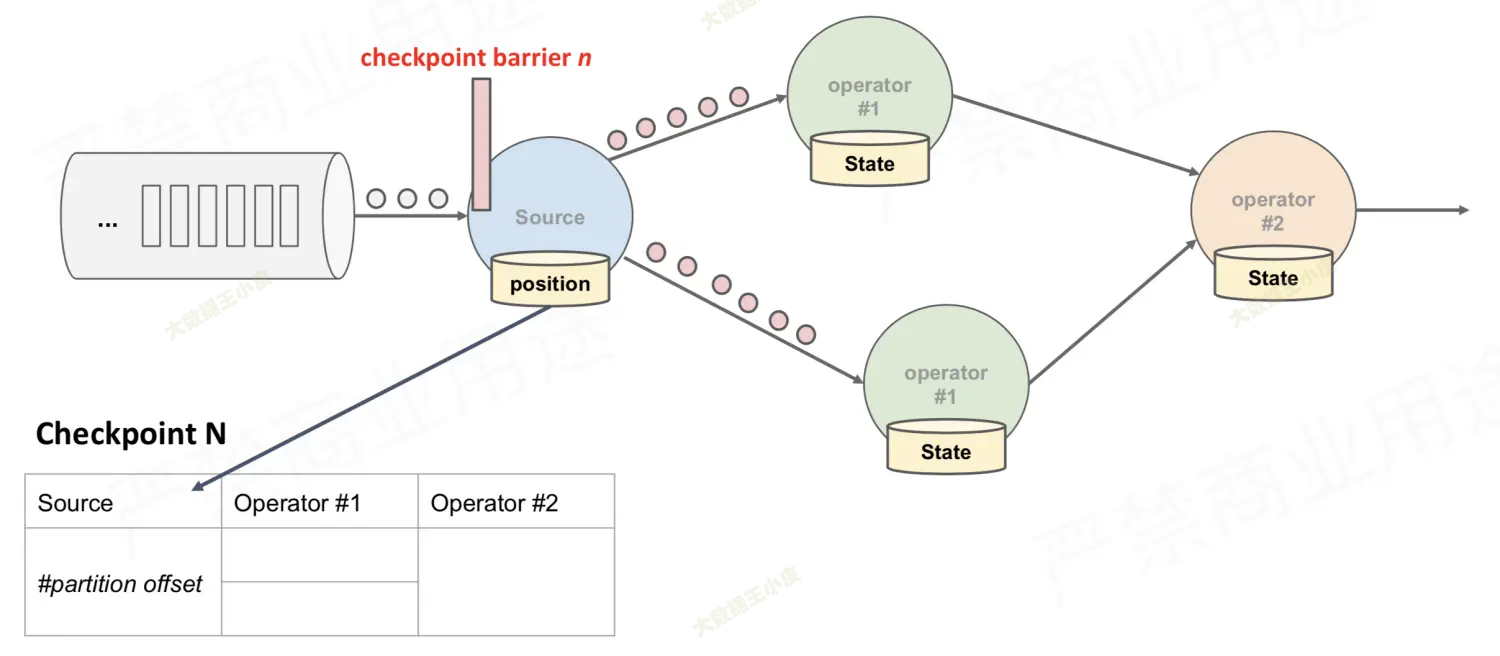
- 接下来,source 将 barrier 拆分为两个,分别发往下游的算子
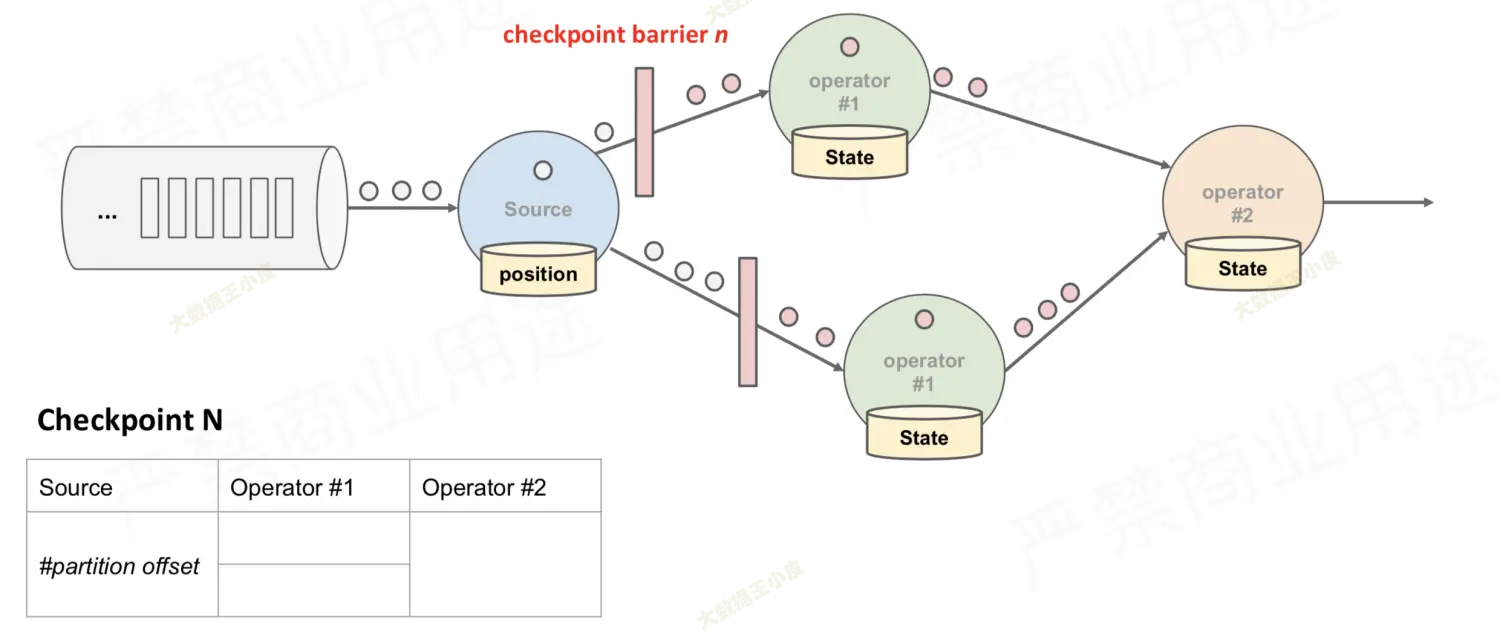
- 下游算子收到 barrier,开始记录状态
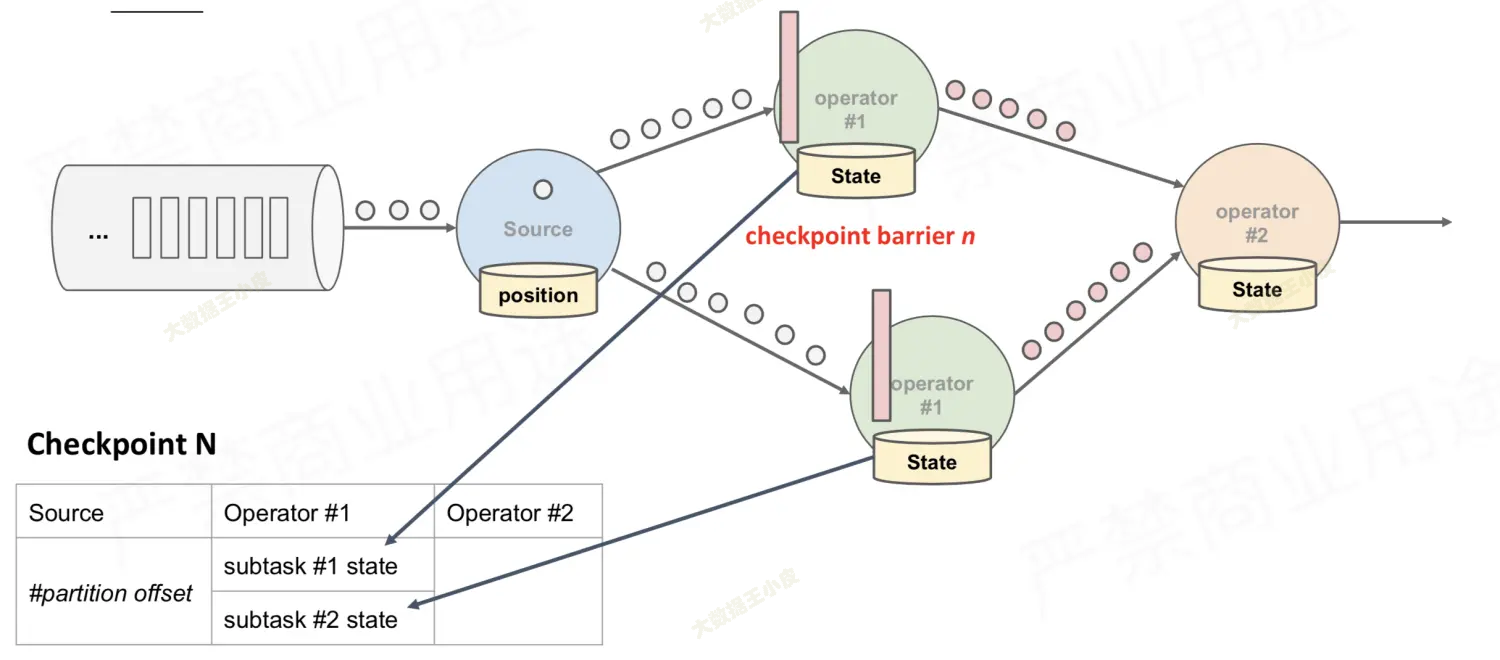
-
关键是最后的 operator#2,它会收到多个 barrier
- barrier 的初始目的是,收到 barrier 表示前面的数据都处理完了,要开始保存状态了
- 两个绿色的节点(operator#1)分别发送 barrier,代表两个 barrier 之前处理过的数据,实际都是第一个蓝色节点(source)barrier 之前的数据。
-
那么最后的橙色节点(operator#2),理应收到所有由绿色节点(operator#1)发送的 barrier,才代表数据已经收全了,可以开始保存状态。
【叫做 barrier 对齐】
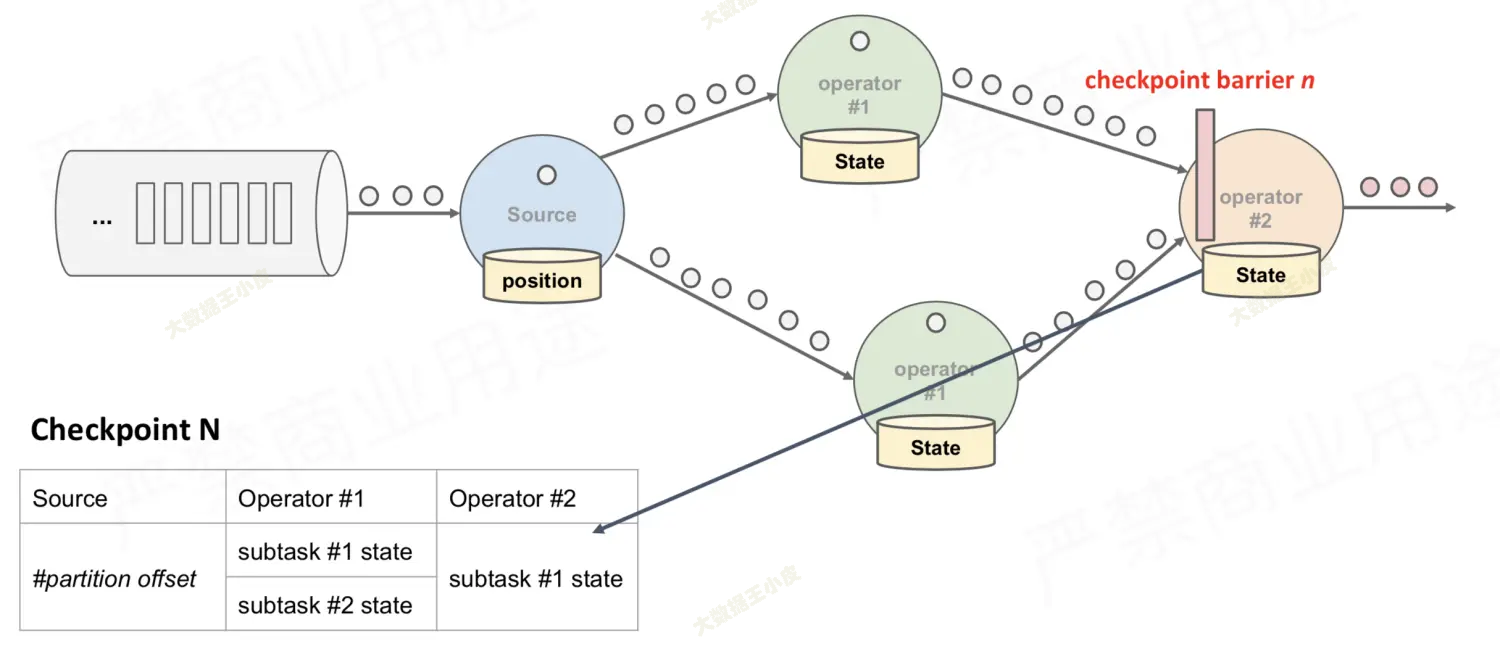
对于多分支合并的情况,在等待所有 barrier 到齐的过程中:
- 先收到 barrier 的分支,还会有数据不断流入
-
为了能做到
精确一次(Exactly-once)
,就不能处理这些数据,需要先缓存起来,否则这个节点的状态就不对了 -
上面一条反过来说,如果不等,直接处理,那么就是
至少一次(At Least Once)
的效果。(想想在故障恢复的时候,是不是就会重复计算了)
如何在不中断运算的前提下产生快照?
前面做快照,我们假设的是节点收到 barrier 后,就不再接收新数据,把当前节点状态保存后,再接收新数据,然后把 barrier 再向后传递。
那,是否必须这样串行来呢?
- 卡住新数据,保存当前状态,这里必须串行,不串行状态就乱了
- 但是,向后发送 barrier 可以同时做,不影响当前节点的保存
那,后面节点保存完了,前面节点还没保存完怎么办?
- 没关系,一次 checkpoint 成功,需要等待所有节点都成功才行,保存的先后顺序无所谓
三、Flink Checkpoint 配置
程序中如何开启 checkpoint
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 开启 checkpoint,并设置间隔 ms
env.enableCheckpointing(1000);
// 模式 Exactly-Once、At-Least-Once
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 两个 checkpoint 之间最小间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 超时时间
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同时执行的 checkpoint 数量(比如上一个还没执行完,下一个已经触发开始了)
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 当用户取消了作业后,是否保留远程存储上的Checkpoint数据
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
checkpoint 存储
Flink 开箱即用地提供了两种 Checkpoint 存储类型:
-
JobManagerCheckpointStorage
- 将 Checkpoint 快照存储在 JobManager 的堆内存中
-
FileSystemCheckpointStorage
- 放到 HDFS 或本地磁盘中
四、小结
本节介绍了 Flink Checkpoint 故障恢复机制。从单机单线程,到多机多线程一步步分析如何实现状态保存和故障恢复。
同时对一致性级别进行了探讨,对程序内部和端到端一致性的实现方式给出了可行的方案。
后续会对 Checkpoint 程序内部实现原理进行剖析。
参考文章:
Flink Checkpoint 深入理解-CSDN博客
漫谈 Flink - Why Checkpoint - Ying
Flink之Checkpoint机制-阿里云开发者社区
(图不错)
Flink 状态一致性、端到端的精确一次(ecactly-once)保证 - 掘金
硬核!八张图搞懂 Flink 端到端精准一次处理语义 Exactly-once(深入原理,建议收藏)-腾讯云开发者社区-腾讯云
- 当非遗邂逅漫展,《如鸢》带来的这场国风联动吸睛无数 2024-10-05
- Rogue牌组构建游戏《Deck of Haunts》Steam页面开放! 2024-10-05
- 炉石传说十周年解谜卡背获得攻略 2024-10-05
- 《绝地求生》工作室获授权将开发《幻兽帕鲁》手游! 2024-10-04
- 像素风冒险《乌鸦国度》主机版宣传片公开!10月发售 2024-10-04
- 世界计划缤纷舞台feat初音未来台服下载地址及游戏介绍 2024-10-03
- 动作RPG《切尔诺贝利人2:禁区》试玩预告片 首曝! 2024-10-03
- 七,MyBatis-Plus 扩展功能:乐观锁,代码生成器,执行SQL分析打印(实操详细使用) 2024-10-02



























